- 异常类型
- 用户自定义异常
- 你必须考虑并遵循的最佳做法
- 1) 永远不要吞下catch块中的异常
- 2) 在你的方法里抛出定义具体的检查性异常
- 3) 捕获具体的子类而不是捕获Exception类
- 4) 永远不要捕获Throwable类
- 5) 始终正确包装自定义异常中的异常,以便堆栈跟踪不会丢失
- 6) 要么记录异常要么抛出异常,但不要一起执行
- 7) finally块中永远不要抛出任何异常
- 8) 始终只捕获实际可处理的异常
- 9) 不要使用printStackTrace()语句或类似的方法
- 10) 如果你不打算处理异常,请使用finally块而不是catch块
- 11) 记住“早throw晚catch”原则
- 12) 清理总是在处理异常之后
- 13) 只从方法中抛出相关异常
- 14) 切勿在程序中使用流程控制异常
- 15) 验证用户输入以在请求处理的早期捕获不利条件
- 16) 一个异常只能包含在一个日志中
- 17) 将所有相关信息尽可能地传递给异常
- 18) 终止掉被中断线程
- 19) 使用模板方法重复try-catch
- 20) 在JavaDoc中记录应用程序中的所有异常
异常类型
JAVA中有三种一般类型的可抛类: 检查性异常(checked exceptions)、非检查性异常(unchecked Exceptions) 和 错误(errors)。
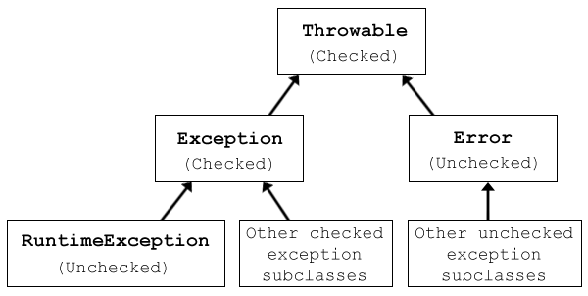
检查性异常(checked exceptions) 是必须在在方法的throws子句中声明的异常。它们扩展了异常,旨在成为一种“在你面前”的异常类型。JAVA希望你能够处理它们,因为它们以某种方式依赖于程序之外的外部因素。检查的异常表示在正常系统操作期间可能发生的预期问题。 当你尝试通过网络或文件系统使用外部系统时,通常会发生这些异常。 大多数情况下,对检查性异常的正确响应应该是稍后重试,或者提示用户修改其输入。
非检查性异常(unchecked Exceptions) 是不需要在throws子句中声明的异常。 由于程序错误,JVM并不会强制你处理它们,因为它们大多数是在运行时生成的。 它们扩展了RuntimeException。 最常见的例子是NullPointerException 。 未经检查的异常可能不应该重试,正确的操作通常应该是什么都不做,并让它从你的方法和执行堆栈中出来。 在高层次的执行中,应该记录这种类型的异常。
错误(errors) 是严重的运行时环境问题,几乎肯定无法恢复。 例如OutOfMemoryError,LinkageError和StackOverflowError, 它们通常会让程序崩溃或程序的一部分。 只有良好的日志练习才能帮助你确定错误的确切原因。
用户自定义异常
任何时候,当用户觉得他出于某种原因想要使用自己的特定于应用程序的异常时,他可以创建一个新的类来适当的扩展超类(主要是它的Exception.java)并开始在适当的地方使用它。 这些用户定义的异常可以以两种方式使用: 1) 当应用程序出现问题时,直接抛出自定义异常
throw new DaoObjectNotFoundException("Couldn't find dao with id " + id);
2) 或者将自定义异常中的原始异常包装并抛出
catch (NoSuchMethodException e) {
throw new DaoObjectNotFoundException("Couldn't find dao with id " + id, e);
}
包装异常可以通过添加自己的消息/上下文信息来为用户提供额外信息,同时仍保留原始异常的堆栈跟踪和消息。 它还允许你隐藏代码的实现细节,这是封装异常的最重要原因。
现在让我们开始探索遵循行业聪明的异常处理的最佳实践。
你必须考虑并遵循的最佳做法
1) 永远不要吞下catch块中的异常
catch (NoSuchMethodException e) {
return null;
}
2) 在你的方法里抛出定义具体的检查性异常
public void foo() throws Exception { //错误方式
}
一定要避免出现上面的代码示例。 它简单地破坏了检查性异常的整个目的。 声明你的方法可能抛出的具体检查性异常。 如果只有太多这样的检查性异常,你应该把它们包装在你自己的异常中,并在异常消息中添加信息。 如果可能的话,你也可以考虑代码重构。
public void foo() throws SpecificException1, SpecificException2 { //正确方式
}
3) 捕获具体的子类而不是捕获Exception类
try {
someMethod();
} catch (Exception e) { //错误方式
LOGGER.error("method has failed", e);
}
捕获异常的问题是,如果稍后调用的方法为其方法声明添加了新的检查性异常,则开发人员的意图是应该处理具体的新异常。 如果你的代码只是捕获异常(或Throwable),你永远不会知道这个变化,以及你的代码现在是错误的,并且可能会在运行时的任何时候中断。
4) 永远不要捕获Throwable类
这是一个更严重的麻烦。 因为java错误也是Throwable的子类。 错误是JVM本身无法处理的不可逆转的条件。 对于某些JVM的实现,JVM可能实际上甚至不会在错误上调用catch子句。
5) 始终正确包装自定义异常中的异常,以便堆栈跟踪不会丢失
catch (NoSuchMethodException e) {
throw new MyServiceException("Some information: " + e.getMessage()); //错误方式
}
这破坏了原始异常的堆栈跟踪,并且始终是错误的。 正确的做法是:
catch (NoSuchMethodException e) {
throw new MyServiceException("Some information: " , e); //正确方式
}
6) 要么记录异常要么抛出异常,但不要一起执行
catch (NoSuchMethodException e) {
//错误方式
LOGGER.error("Some information", e);
throw e;
}
正如在上面的示例代码中,记录和抛出异常会在日志文件中产生多条日志消息,代码中存在单个问题,并且让尝试挖掘日志的工程师生活得很糟糕。
7) finally块中永远不要抛出任何异常
try {
someMethod(); //Throws exceptionOne
} finally {
cleanUp(); //如果finally还抛出异常,那么exceptionOne将永远丢失
}
只要cleanUp()永远不会抛出任何异常,上面的代码没有问题。 但是如果someMethod()抛出一个异常,并且在finally块中,cleanUp()也抛出另一个异常,那么程序只会把第二个异常抛出来,原来的第一个异常(正确的原因)将永远丢失。 如果你在finally块中调用的代码可能会引发异常,请确保你要么处理它,要么将其记录下来。 永远不要让它从finally块中抛出来。
8) 始终只捕获实际可处理的异常
catch (NoSuchMethodException e) {
throw e; //避免这种情况,因为它没有任何帮助
}
这是最重要的概念。 不要为了捕捉异常而捕捉,只有在想要处理异常时才捕捉异常,或者希望在该异常中提供其他上下文信息。 如果你不能在catch块中处理它,那么最好的建议就是不要只为了重新抛出它而捕获它。
9) 不要使用printStackTrace()语句或类似的方法
完成代码后,切勿忽略printStackTrace()。 你的同事可能会最终得到这些堆栈,并且对于如何处理它完全没有任何知识,因为它不会附加任何上下文信息。
10) 如果你不打算处理异常,请使用finally块而不是catch块
try {
someMethod(); //Method 2
} finally {
cleanUp(); //do cleanup here
}
这也是一个很好的做法。 如果在你的方法中你正在访问Method 2,而Method 2抛出一些你不想在method 1中处理的异常,但是仍然希望在发生异常时进行一些清理,然后在finally块中进行清理。 不要使用catch块。
11) 记住“早throw晚catch”原则
这可能是关于异常处理最著名的原则。 它基本上说,你应该尽快抛出(throw)异常,并尽可能晚地捕获(catch)它。 你应该等到你有足够的信息来妥善处理它。
这个原则隐含地说,你将更有可能把它放在低级方法中,在那里你将检查单个值是否为空或不适合。 而且你会让异常堆栈跟踪上升好几个级别,直到达到足够的抽象级别才能处理问题。
12) 清理总是在处理异常之后
如果你正在使用数据库连接或网络连接等资源,请确保清除它们。 如果你正在调用的API仅使用非检查性异常,则仍应使用try-finally块来清理资源。 在try模块里面访问资源,在finally里面最后关闭资源。 即使在访问资源时发生任何异常,资源也会优雅地关闭。
13) 只从方法中抛出相关异常
相关性对于保持应用程序清洁非常重要。 一种尝试读取文件的方法; 如果抛出NullPointerException,那么它不会给用户任何相关的信息。 相反,如果这种异常被包裹在自定义异常中,则会更好。 NoSuchFileFoundException则对该方法的用户更有用。
14) 切勿在程序中使用流程控制异常
我们已经阅读过很多次,但有时我们还是会在项目中看到开发人员尝试为应用程序逻辑而使用异常的代码。 永远不要这样做。 它使代码很难阅读,理解和丑陋。
15) 验证用户输入以在请求处理的早期捕获不利条件
始终要在非常早的阶段验证用户输入,甚至在达到实际controller之前。 它将帮助你把核心应用程序逻辑中的异常处理代码量降到最低。 如果用户输入出现错误,它还可以帮助你使与应用程序保持一致。
例如:如果在用户注册应用程序中,你遵循以下逻辑:
1)验证用户 2)插入用户 3)验证地址 4)插入地址 5)如果出问题回滚一切
这是非常不正确的做法。 它会使数据库在各种情况下处于不一致的状态。 首先验证所有内容,然后将用户数据置于dao层并进行数据库更新。 正确的做法是:
1)验证用户 2)验证地址 3)插入用户 4)插入地址 5)如果问题回滚一切
16) 一个异常只能包含在一个日志中
LOGGER.debug("Using cache sector A");
LOGGER.debug("Using retry sector B");
不要这样做。
对多个LOGGER.debug()调用使用多行日志消息可能在你的测试用例中看起来不错,但是当它在具有400个并行运行的线程的应用程序服务器的日志文件中显示时,所有转储信息都是相同的日志文件,你的两个日志消息最终可能会在日志文件中间隔1000行,即使它们出现在代码的后续行中。
像这样做:
LOGGER.debug("Using cache sector A, using retry sector B");
17) 将所有相关信息尽可能地传递给异常
有用且信息丰富的异常消息和堆栈跟踪也非常重要。 如果你的日志不能确定任何事情(有效内容不全或很难确定问题原因), 那要日志有什么用? 这类的日志只是你代码中的装饰品。
18) 终止掉被中断线程
while (true) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {} //别这样做
doSomethingCool();
}
InterruptedException是你的代码的一个提示,它应该停止它正在做的事情。 线程中断的一些常见用例是active事务超时或线程池关闭。 你的代码应该尽最大努力完成它正在做的事情,并且完成当前的执行线程,而不是忽略InterruptedException。 所以要纠正上面的例子:
while (true) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
break;
}
}
doSomethingCool();
19) 使用模板方法重复try-catch
在你的代码中有100个类似的catch块是没有用的。 它增加代码的重复性而且没有任何的帮助。 对这种情况要使用模板方法。
例如,下面的代码尝试关闭数据库连接。
class DBUtil{
public static void closeConnection(Connection conn){
try{
conn.close();
} catch(Exception ex){
//Log Exception - Cannot close connection
}
}
}
这种类型的方法将在你的应用程序的成千上万个地方使用。 不要把这块代码放的到处都是,而是定义顶层的方法,并在下层的任何地方使用它:
public void dataAccessCode() {
Connection conn = null;
try{
conn = getConnection();
....
} finally{
DBUtil.closeConnection(conn);
}
}
20) 在JavaDoc中记录应用程序中的所有异常
把注释(javadoc)运行时可能抛出的所有异常作为一种习惯。 也要尽可能包括可行的方案,用户应该关注这些异常发生的情况。