1.dom4j解析xml
setting.xml
<?xml version="1.0" encoding="UTF-8"?>
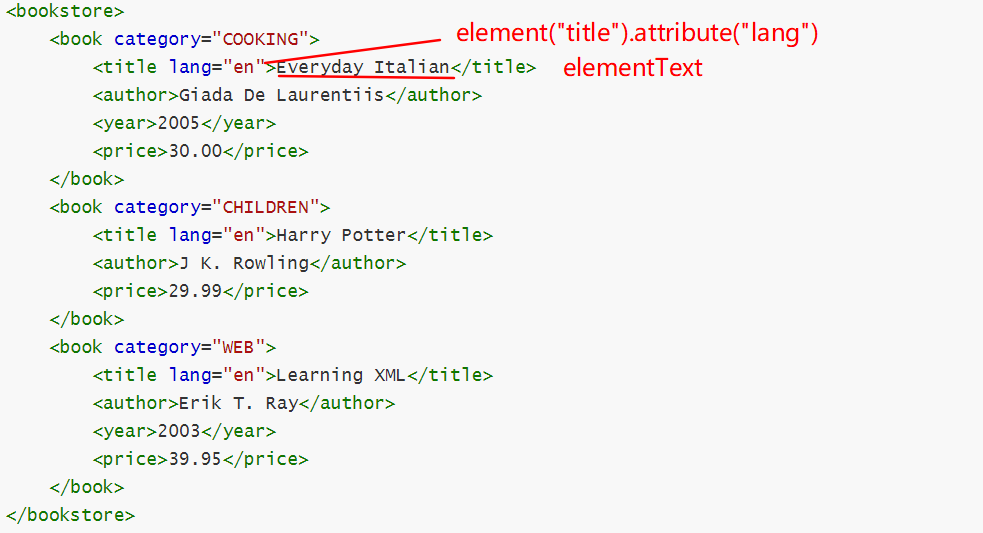
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
package com.beiwu.xml;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentType;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.xml.sax.EntityResolver;
import java.io.File;
import java.util.Iterator;
/**
* @author zhoubing
* @date 2020-08-12 11:56
*/
public class ParseXmlLearn {
public static void main(String[] args) throws DocumentException {
File file = new File("D:\\ideaprojects\\spi_learn\\test.xml");
SAXReader saxReader = new SAXReader();
Document doc = saxReader.read(file);
Element rootElement = doc.getRootElement();
DocumentType docType = doc.getDocType();
EntityResolver entityResolver = doc.getEntityResolver();
System.out.println(doc.getXMLEncoding());
Iterator iterator = rootElement.elementIterator("book");
Element docChild;
while (iterator.hasNext()){
docChild = (Element) iterator.next();
// 获得元素中的文本
String title = docChild.elementText("title");
String author = docChild.elementText("author");
String price = docChild.elementText("price");
// 获取元素上面的标签
String lang = docChild.attributeValue("category");
// 获取子元素的标签
String titleAttribute = docChild.element("title").attributeValue("lang");
System.out.println("title = " + title);
System.out.println("author = " + author);
System.out.println("price = " + price);
System.out.println("lang = " + lang);
System.out.println("titleAttribute = " + titleAttribute);
System.out.println("=================================");
}
}
}
2.w3c解析xml
public static org.w3c.dom.Document getDocumentByW3c(String sourcePath) {
File file = new File(sourcePath);
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
org.w3c.dom.Document doc = builder.parse(file);
return doc;
} catch (Exception e) {
System.err.println("读取该xml文件失败");
e.printStackTrace();
}
return null;
}
public static void testGetDocumentByW3c() {
org.w3c.dom.Document doc = getDocumentByW3c("D:\\ideaprojects\\spi_learn\\test.xml");
String xmlVersion = doc.getXmlVersion();
//读取xml内部节点集合
org.w3c.dom.NodeList nlst = doc.getElementsByTagName("book");
//遍历集合内容
for (int i = 0; i < (nlst).getLength(); i++) {
String title = doc.getElementsByTagName("title").item(i).getFirstChild().getNodeValue();
String author = doc.getElementsByTagName("author").item(i).getFirstChild().getNodeValue();
String price = doc.getElementsByTagName("price").item(i).getFirstChild().getNodeValue();
System.err.println("标题" + title);
System.err.println("作者" + author);
System.err.println("价格" + price);
}
}
不建议使用该方法解析xml